资料内容:
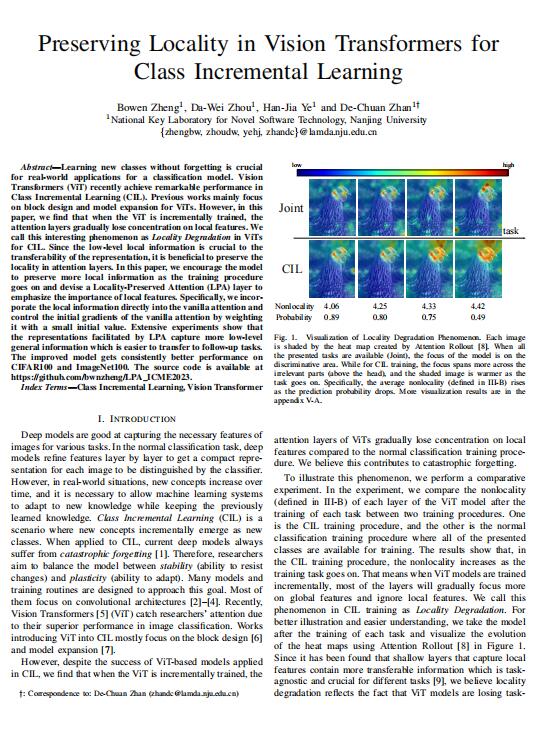
Deep models are good at capturing the necessary features ofimages for various tasks. In the normal classification task, deepmodels refine features layer by layer to get a compact repre-sentation for each image to be distinguished by the classifier.However, in real-world situations, new concepts increase overtime,and it is necessary to allow machine learning systemsto adapt to new knowledge while keeping the previouslylearned knowledge. Class Incremental Learning (CIL) is ascenario where new concepts incrementally emerge as newclasses. When applied to CIL,current deep models alwayssuffer from catastrophic forgeting [1]. Therefore , researchersaim to balance the model between stabiliry (ability to resistchanges) and plasticity (ability to adapt). Many models andtraining routines are designed to approach this goal. Most ofthem focus on convolutional architectures [2]-[4]. Recently,Vision Transformers [5](ViT) catch researchers' attention dueto their superior performance in image classification. Worksintroducing ViT into CIL mostly focus on the block design [6]and model expansion [7].

